
Deployment eines eigenen Sprachmodells
Large Language Models (LLMs) haben die Art und Weise revolutioniert, wie wir mit Texten umgehen und maschinelles Lernen anwenden. Sie bieten eine beeindruckende Fähigkeit zur Textgenerierung und ein tieferes Verständnis von Sprache im Vergleich zu kleineren Modellen des Natural Language Processing (NLP). Welche Unterschiede es gibt, welche Herausforderungen es beim Deployment von LLMs zu meistern gilt und wann es sinnvoll ist, auf kleinere Modelle zurückzugreifen, erläutert dieser Artikel. Außerdem werden wir die Vor- und Nachteile des selbst gehosteten LLMs diskutieren und die Kriterien für die Entscheidung zwischen On-Premises und Cloud erläutern.
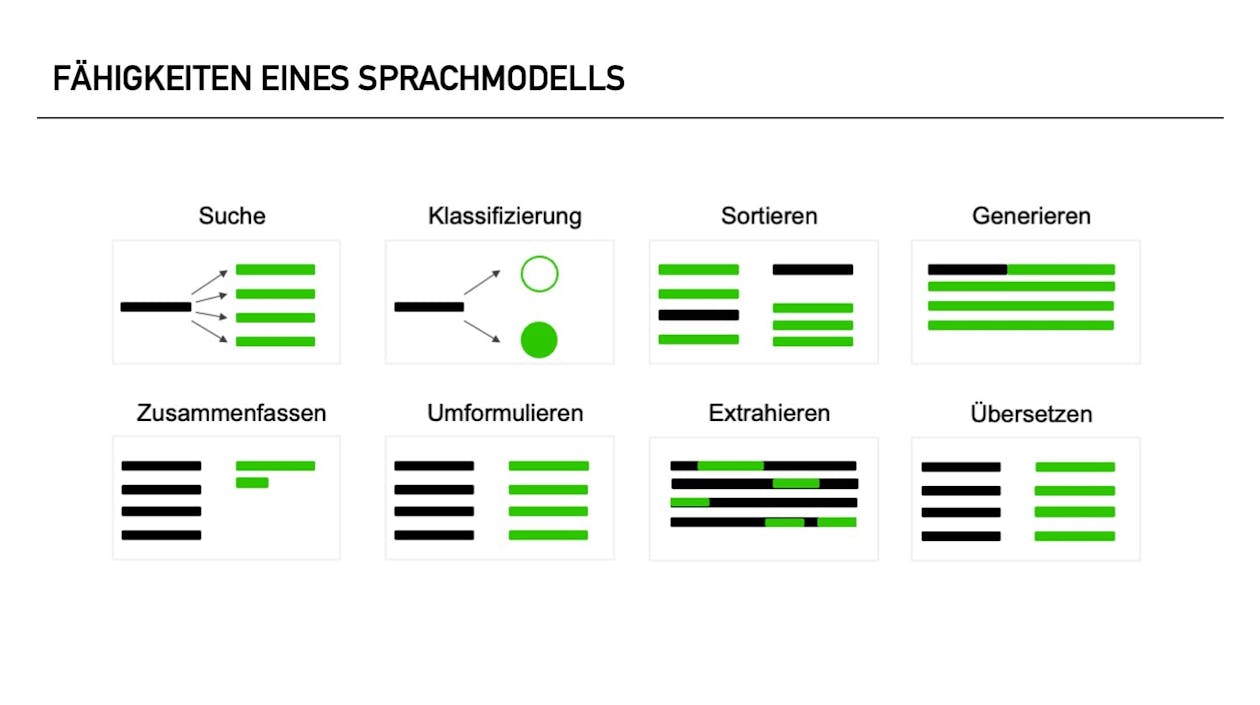
Was unterscheidet Large Language Models von kleineren NLP-Modellen?
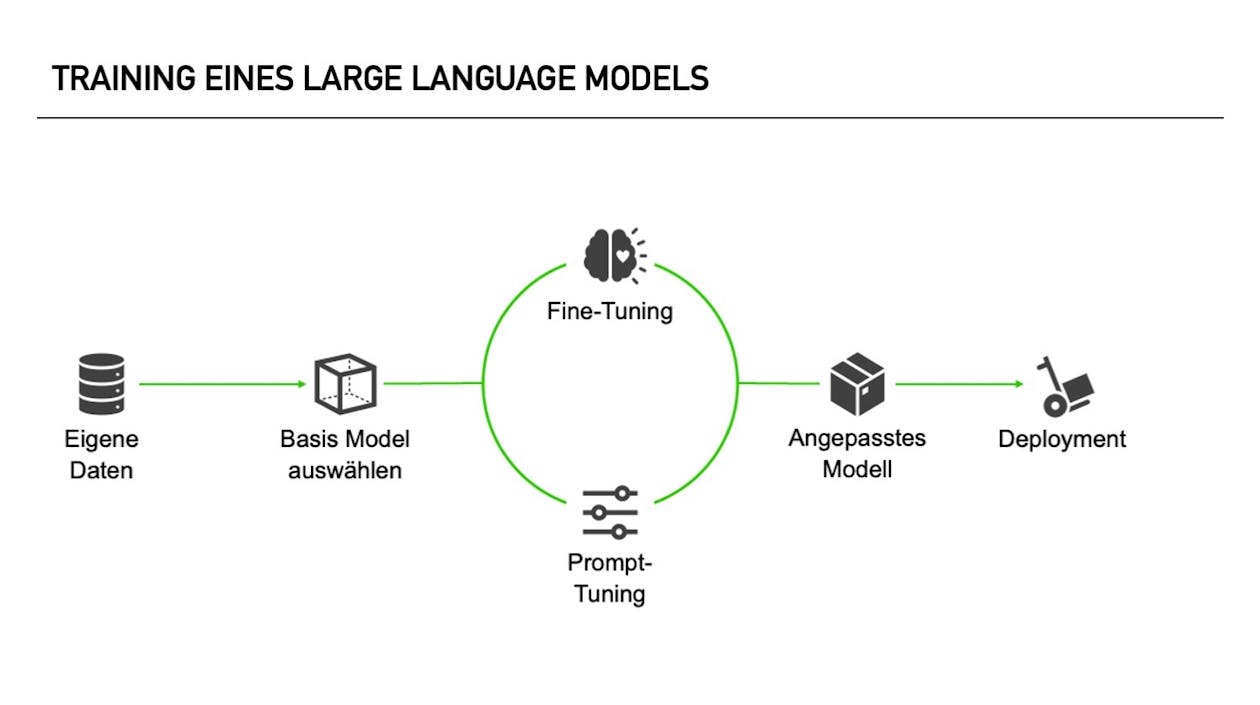
Wie trainiert man ein LLM auf eigene Daten?
Warum oder wann braucht Ihr Unternehmen ein fein abgestimmtes Large Language Model?
Deployment von Large Language Models
Vor- und Nachteile für ein selbst gehostetes Large Language Model

Kriterien für die Entscheidung zwischen On-Premises und Cloud
Rechenbeispiel für das Deployment eines LLMs
Angenommen, ein Unternehmen plant das Deployment eines LLMs in der Lambda Cloud. Das Modell soll 1.000 Anfragen pro Stunde verarbeiten, wobei jede Anfrage drei Sekunden Rechenzeit benötigt. Diese Anforderungen können je nach Modellgröße schon von einer 80 vRAM und NVIDIA H100 GPU Instanz erfüllt werden. Der Cloud-Anbieter berechnet 0,0373€ pro Sekunde Rechenzeit und 0,0001€ pro Anfrage für Datenübertragungskosten.
Rechenbeispiel für das Deployment eines LLMs
Angenommen, ein Unternehmen plant das Deployment eines LLMs in der Lambda Cloud. Das Modell soll 1.000 Anfragen pro Stunde verarbeiten, wobei jede Anfrage drei Sekunden Rechenzeit benötigt. Diese Anforderungen können je nach Modellgröße schon von einer 80 vRAM und NVIDIA H100 GPU Instanz erfüllt werden. Der Cloud-Anbieter berechnet 0,0373€ pro Sekunde Rechenzeit und 0,0001€ pro Anfrage für Datenübertragungskosten.[1]
Die Kosten pro Stunde berechnen sich wie folgt:
- Rechenzeit: 100 Anfragen/Stunde * 3 Sekunden/ Anfrage * 0,0373€/Sekunde = 11,19€/Stunde
- Datenübertragungskosten: 100 Anfragen/ Stunde * 0,0001€ /Anfrage = 0,1€/Stunde
- Gesamtkosten: 0,1€/Stunde + 11,19€/ Stunde = 11,20€/Stunde
Bei der Annahme von 250 Arbeitstagen im Jahr, an denen das Modell zur Verfügung stehen soll, wären das bei einer Bereitstellungsdauer von ca. 12 Stunden am Tag 33.600€.
Dabei sind noch keine Arbeitsstunden für die Wartung bzw. das Anpassen des Modells berücksichtigt. Darüber hinaus gehen wir hier von einer bedarfsorientierten Bereitstellung aus, sodass der Service nicht dauerhaft läuft, sondern nur bei Bedarf hochgefahren wird.
Lohnt sich das? Das kommt auf den Use-Case an. Ein klassisches Szenario ist die Unterstützung des First Level Support mit Sprachmodellen. Die Sprachmodelle können viele eher weniger Komplexe Probleme von Kunden lösen, sodass die Mitarbeitenden im Support sich um die wichtigen Fälle kümmern. Das entlastet Ihre Mitarbeiter und spart deutlich Überstunden.
[1] Ungefähre Schätzung basierend auf https://lambdalabs.com/service/gpu-cloud/pricing
Unterschiede zwischen On-Premises und Cloud
Fazit
Wir unterstützen Sie gerne bei Ihrem Projekt!

