


Der Hype um KI (Teil 2) – Wie funktioniert Künstliche Intelligenz eigentlich?
In unserem ersten Artikel haben wir auf die Relevanz von künstlicher Intelligenz (KI) aufmerksam gemacht. Um ein realistischeres Verständnis dafür zu bekommen, was mit KI-Systemen möglich ist und welche Grenzen sie haben, bieten wir in diesem Beitrag einen tieferen Einblick in die Technologie. Wir beleuchten dafür die Haupttechnologie hinter dem Begriff KI: das maschinelle Lernen. Innerhalb des maschinellen Lernens gibt es verschiedene Ansätze und Techniken, von denen künstliche neuronale Netze besonders hervorzuheben sind.
Maschinelles Lernen
Das Forschungsgebiet des maschinellen Lernens konzentriert sich darauf, das „Lernen“ aus Daten zu ermöglichen. Statt starren, schrittweise auszuführenden Algorithmen zu folgen, ermöglicht maschinelles Lernen einem System, Muster, Zusammenhänge und Abhängigkeiten in Daten zu erkennen und diese zur Vorhersage oder Kategorisierung von Informationen zu nutzen.
Die unterschiedlichen Ansätze des maschinellen Lernens lassen sich dabei in drei Kategorien einteilen:
- Überwachtes Lernen (Supervised Learning) fußt auf dem Gedanken, dass einem System die Welt erklärt wird. Es wird mit Eingabe-Ausgabe-Paaren trainiert, wobei jeder Datenpunkt aus einer Eingabe und dem zugehörigen gewünschten Ergebnis besteht. Das System „lernt“ die Beziehung zwischen diesen beiden.
Ein Beispiel hierfür wäre ein Eingabe-Ausgabe-Paar, das aus einem Katzenbild und dem gewünschten Begriff „Katze“ besteht. Durch tausende solcher Paare erlernt das System, wie eine Katze aussieht. Dieser Ansatz hat sich in den letzten 20 Jahren in verschiedenen Mustererkennungswettbewerben, wie z.B. bei der Erkennung von Handschriften, als überlegen gegenüber traditionell programmierten Algorithmen erwiesen. Der Versuch, das Aussehen von Buchstaben oder einer Katze mathematisch zu definieren, ist zu komplex und fehleranfällig. - Unüberwachtes Lernen (Unsupervised Learning): Hierbei werden Systeme mit Daten trainiert, die keine vorgegebenen Ergebnisse haben. Das System analysiert und erkundet die Daten gewissermaßen selbstständig, um Muster, Zusammenhänge und Strukturen zu identifizieren. So lassen sich beispielsweise ähnliche Datensätze finden und Gruppen zuordnen. Ein weiterer Anwendungsfall ist die Erkennung von Datensätzen, die sich deutlich von anderen unterscheiden, bekannt als Ausreißeranalyse.
Im Gegensatz zu anderen Ansätzen, bei denen Menschen bestimmte Betrachtungsdimensionen und Vorgehensweisen festlegen müssen, ermöglicht das unüberwachte Lernen eine automatisierte Datenanalyse. Dies reduziert nicht nur den manuellen Aufwand, sondern minimiert auch das Risiko menschlicher Fehler bei der Auswahl relevanter Betrachtungsdimensionen. - Bestärkendes Lernen (Reinforcement Learning): Bei diesem Ansatz wird einem System beigebracht, wie es Entscheidungen in einer Umgebung trifft. Eine oder mehrere Aktionen des Systems führen zu einem mehr oder weniger präferierten neuen Zustand der Umgebung. Die Zustandsänderung wird über ein Belohnungssystem (ausgeprägt durch eine mathematische Formel) bewertet. Die Bewertung wird als Feedback in Form eines Bonus oder Malus dem System gespiegelt. Das System modifiziert das eigene Verhalten, um seine Belohnung zu maximieren.
Bestärkendes Lernen eignet sich besonders für hochkomplexe Herausforderungen, bei denen die explizite Programmierung von richtigen Handlungen nicht möglich ist. Das System wird gewissermaßen mit Belohnungen zu einem gewünschten Verhalten erzogen. Als Anwendungsbeispiele seien hier personalisierte Empfehlungen, Robotik und Ressourcenmanagement genannt.
Nachdem ein System auf einen bestimmten Datensatz trainiert wurde, wird das System anhand von Testdaten, die es während des Trainings nicht gesehen hat, evaluiert, um seine Genauigkeit und Leistungsfähigkeit zu bestimmen. Sobald die Ergebnisse zufriedenstellend sind, kann das trainierte System in Anwendungen implementiert werden. Dort wird es mit neuen, bisher ungesehenen Daten konfrontiert, um Vorhersagen basierend auf Erfahrungswerten zu treffen.
Innerhalb der unterschiedlichen Ansätze des maschinellen Lernens findet eine Vielzahl von Techniken und Ansätzen Anwendung. Das Herzstück vieler Systeme sind künstliche neuronale Netze. Ihre Beliebtheit rührt daher, dass sie für eine Fülle komplexer Aufgaben, wie die Bild- und Spracherkennung, besonders geeignet sind. Um ihre Funktionsweise zu verstehen, betrachten wir im Folgenden ihren Aufbau und die verwendeten Mechanismen.
Künstliche neuronale Netze
Die Grundidee hinter künstlichen neuronalen Netzen ist vom menschlichen Gehirn inspiriert. In einem solchen Netz bilden individuelle Knotenpunkte, sogenannte Neuronen, und deren Verbindungen ein komplexes, miteinander verflochtenes System.
Ein einfaches neuronales Netz gliedert sich dabei in 2 bis n Schichten:
- Eine Eingangsschicht, die Daten aufnimmt,
- eine oder mehrere sogenannte versteckte Schichten, in denen die eigentliche Datenverarbeitung vorgenommen wird, und
- eine Ausgangsschicht, die das Ergebnis des Netzes ausgibt.
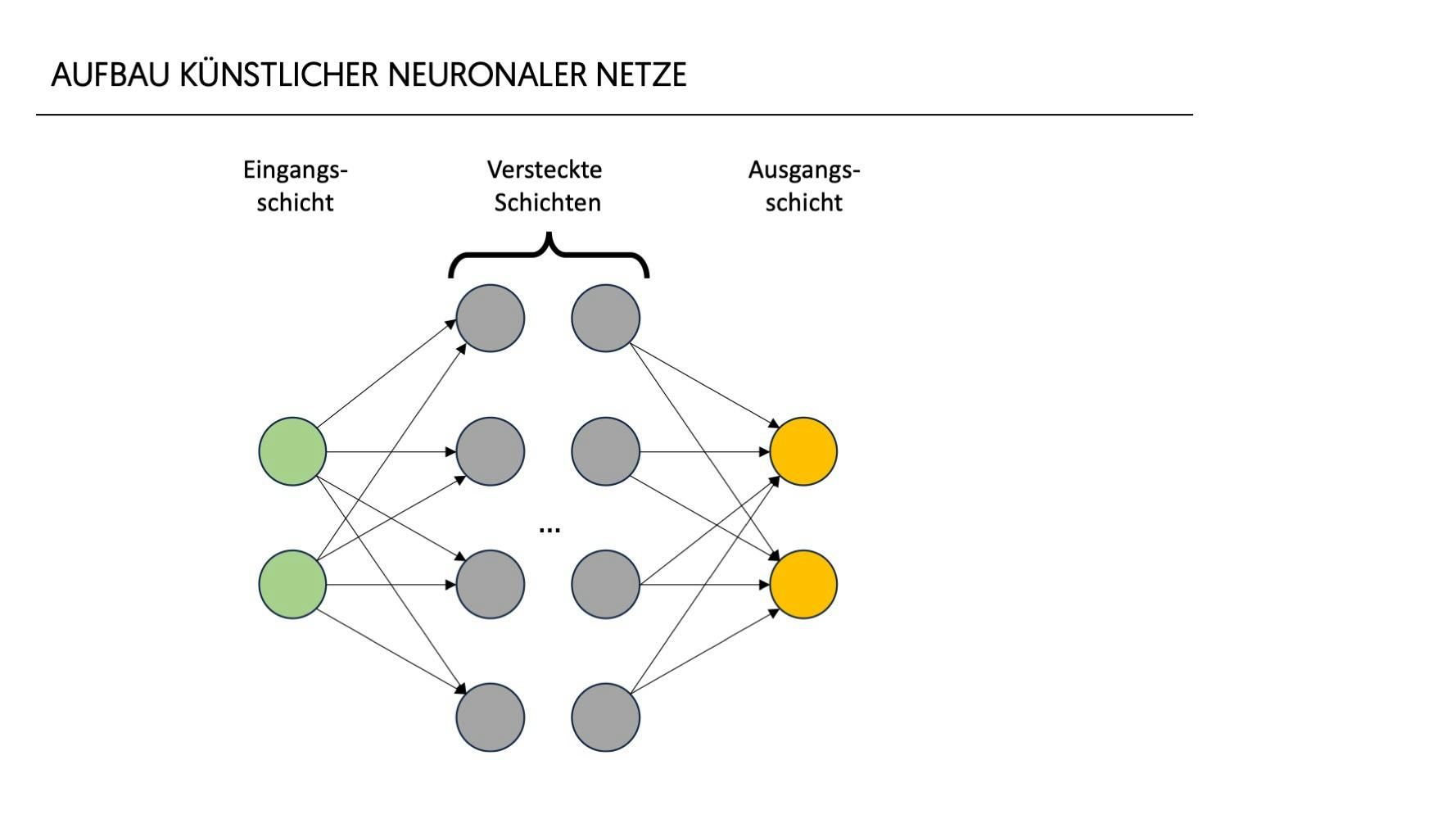
Informationen durchlaufen das Netz, indem sie von Schicht zu Schicht und von Neuron zu Neuron weitergegeben werden. Alle Verbindung und alle Neuronen haben eine Gewichtung, die während des Trainingsprozesses angepasst werden und die Relevanz jeweiligen der Verbindung bzw. des Neurons repräsentiert. Jede Schicht und jedes Neuron tragen zum Gesamtergebnis bei. Das Zusammenspiel der einzelnen Neuronen und ihre Gewichtungen sorgen dafür, dass das Modell am Ende die gewünschten Informationen ausgeben kann.
Die Tiefe des Netzes – also die Anzahl der verstecken Schichten zwischen Eingabe- und Ausgabeschicht – beeinflusst dabei seine Fähigkeit, komplexe Beziehungen in den Daten zu modellieren. Der häufig verwendete Begriff „Deep Learning“ bezieht sich auf künstliche neuronale Netze mit mindestens einer versteckten Schicht. Während einfache Netze ohne versteckte Schichten für bestimmte, weniger komplexe Aufgaben theoretisch geeignet sein könnten, lässt sich allerdings die Sinnhaftigkeit von solchen Netzen stark in Zweifel ziehen. Es wäre nur eine sehr geringe Komplexität fassbar.
Deep-dive: Neuron
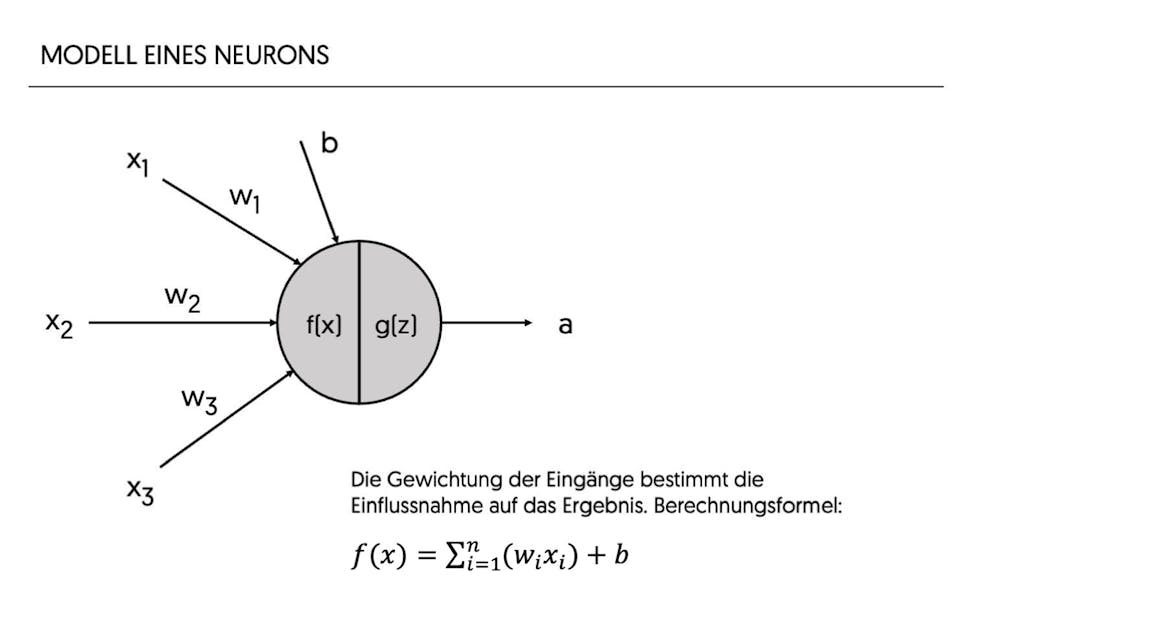
Betrachten wir zum besseren Verständnis ein einzelnes Neuron im Detail. Das Neuron ist die grundlegende Einheit eines jeden neuronalen Netzes. Im Folgenden werden Eingaben, Gewichtungen, Bias und Aktivierungsfunktionen beschrieben.
Deep-dive: Neuron
Das Neuron ist die grundlegende Einheit eines jeden künstlichen neuronalen Netzes. Es empfängt Eingaben x1 – xn, verarbeitet sie und gibt ein Ergebnis a aus. Jede Eingabe x eines Neurons wird mit einer entsprechenden Gewichtung w multipliziert. Diese gewichteten Eingaben werden summiert. Ein zusätzlicher Wert, der sogenannte Bias b, wird hinzugefügt, um das Modell flexibler und anpassungsfähiger zu machen und die Verschiebung der Aktivierungsfunktion zu steuern. Die Gewichtungen der Eingänge modellieren, wie stark die jeweiligen Eingänge das Ergebnis eines Neurons beeinflussen, wohingegen der Bias modelliert, wie wichtig das Neuron für das Ergebnis des Netzes ist. Die Berechnung erfolgt entsprechend nebenstehender Formel.
Die resultierende Summe z wird dann durch eine Aktivierungsfunktion g(z) geleitet, um den Ausgang des Neurons zu erhalten: a = g(f(x))
Die Wahl der Aktivierungsfunktion g kann die Performance des Netzes stark beeinflussen und hängt oft von der Art des zu lösenden Problems ab. Zwei gängige Aktivierungsfunktionen sind:
- Die Sigmoid-Funktion gibt Werte zwischen 0 und 1 aus und wird oft in binären Klassifikationsproblemen verwendet. Die Sigmoid-Funktion könnte beispielsweise in der Ausgabeschicht eines neuronalen Netzes eingesetzt werden, um zu entscheiden, ob eine E-Mail Spam (1) oder nicht (0) ist, basierend auf verschiedenen Merkmalen der E-Mail.
- Die ReLU (Rectified Linear Unit) Aktivierungsfunktion setzt alle negativen Werte auf Null und lässt positive Werte unverändert. Sie wird oft in tieferen Netzen bevorzugt, da sie das Training beschleunigen kann. Sie findet beispielsweise in Netzen zur Bildklassifikation Anwendung, um komplexe, hierarchische Muster in Bildern zu erkennen und zu lernen, welche zur Identifikation von Objekten in Bildern beitragen.
Die Ausgabe eines Neurons dient dann wiederum als Input für die nächsten Neuronen.
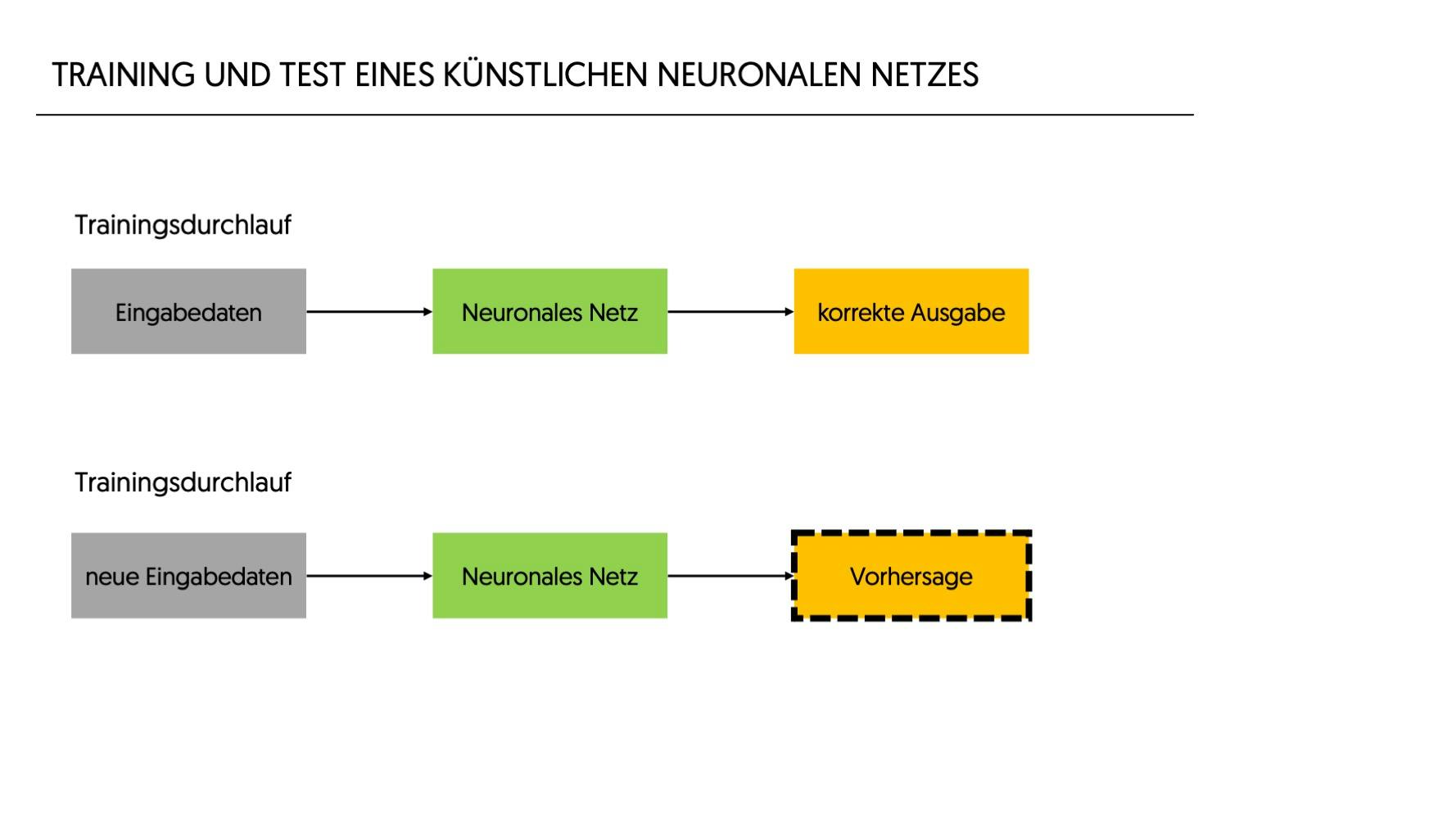
Training eines Netzes
Der Lernprozess eines künstlichen neuronalen Netzes wird Training genannt. Vor dem Training werden die Gewichtungen und Biases in neuronalen Netzen auf zufällige Werte gesetzt. Das bedeutet, dass im Modell noch keine Informationen gespeichert sind und die einzelnen Neuronen noch keine optimierten Gewichtungen oder Biases aufweisen. Ziel des Trainings ist es, diese Gewichtungen und Biases im Laufe des Trainings so anzupassen, dass die Ausgabe des Netzes den gewünschten Ergebnissen so nahe wie möglich kommt. Die eingeschränkte Fähigkeit eines einzelnen Neurons täuscht über die hohe Komplexität und die unzähligen Anwendungsfälle hinweg, wenn ein Geflecht von Tausenden, Millionen oder Milliarden von Neuronen in einem Netz zusammenwirken.
Ein zentrales Konzept des Trainings ist der „Verlust“ (oder Fehler), oft als Verlustfunktion bezeichnet. Er gibt an, wie weit die Vorhersagen des Netzes von den tatsächlichen Ergebnissen abweichen. Es gibt verschiedene Verlustfunktionen und die Wahl hängt von der spezifischen Aufgabe des künstlichen neuronalen Netzes ab. Um diesen Verlust zu minimieren, wird ein Optimierungsverfahren verwendet. Der Gradientenabstieg ist ein häufig verwendetes Optimierungsverfahren, das iterativ die Gewichte und Biases in die Richtung anpasst, die den Verlust am stärksten reduziert, basierend auf dem Konzept der ersten Ableitung.
Beim überwachten Lernen wird der Verlust L als Differenz zwischen der vorhergesagten Ausgabe ý und der tatsächlichen Ausgabe y definiert:
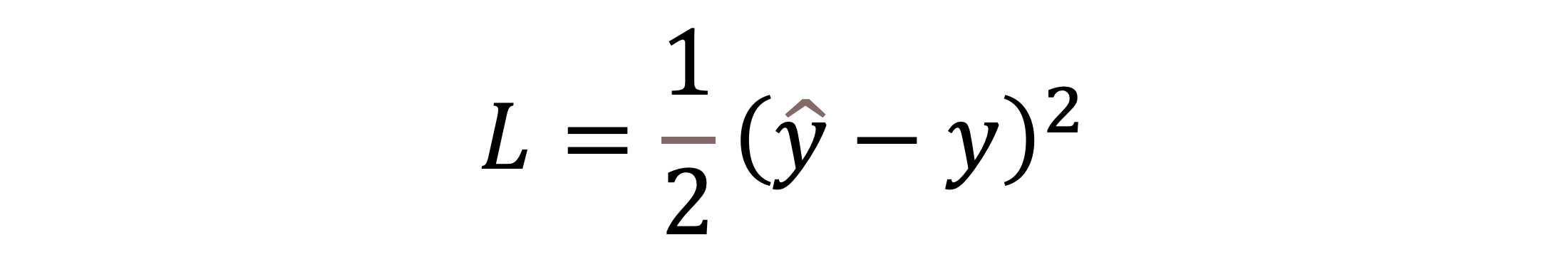
Ein essenzieller Schritt im Training eines neuronalen Netzes ist die Backpropagation. Hierbei wird der Fehler/ Verlust vom Ausgang des Netzes rückwärts durch die Anwendung des Optimierungsverfahrens auf alle Schichten und Neuronen zurückgerechnet. Dieses spezielle Verfahren berechnet den Gradienten der Verlustfunktion bezüglich jedes Gewichts und Bias im Netz, wie stark Gewichtung und Bias eines jeden Neurons zum Gesamtfehler beitragen. Mit dieser Information werden die Gewichtungen und Biases entsprechend angepasst. Dieses Verfahren wird mit verschiedensten Daten so lange wiederholt, bis die Vorhersage hinreichend optimiert ist.
Das künstliche neuronale Netz ist jetzt trainiert und hat gewonnene Erfahrungen durch die Modifikation von Gewichtungen und Biases gespeichert.
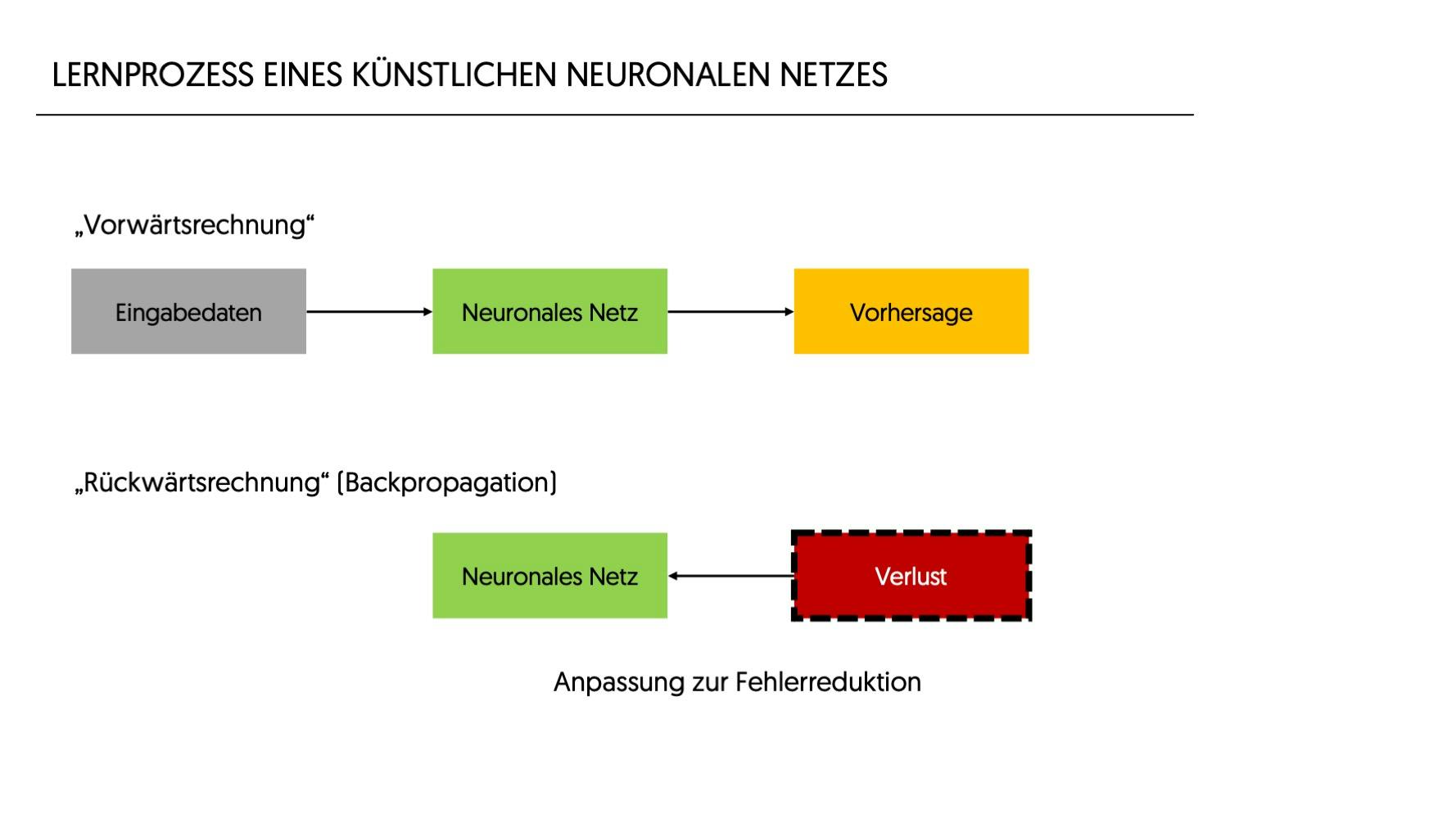
Zusammenfassend sind neuronale Netze komplexe, verflochtene Systeme, die durch Training in der Lage sind, Muster und Zusammenhänge in Daten zu erkennen und darauf basierende Entscheidungen zu treffen. Allerdings kann die Entscheidungsfindung eines gut trainierten Netzes aufgrund der zugrundeliegenden Mathematik und der Vielzahl von Neuronen nicht mehr nachvollzogen oder erklärt werden, weshalb man im Zusammenhang mit KIs häufig von einer „Black Box“ spricht. Ferner ist das Training, d. h. die Optimierung und die Backpropagation außerordentlich rechenintensiv. Hierdurch kommen auch moderne Supercomputer schnell an Grenzen.
Optimierte Ansätze
Nachdem wir die Funktionsweise von einzelnen Neuronen und deren Verknüpfung in neuronalen Netzen betrachtet haben, stellt sich die Frage: Wie entwickelt sich ein System aus diesen Grundbausteinen zu den hochentwickelten KI-Modellen, die wir heute kennen und nutzen?
Die Antwort liegt in der fortschreitenden Entwicklung und Verfeinerung der Netzarchitekturen sowie in der Integration innovativer Mechanismen. Während einfache neuronale Netze bereits bemerkenswerte Aufgaben bewältigen können, erfordern komplexere Probleme, wie etwa die Verarbeitung von natürlicher Sprache oder detaillierte Bildanalysen, weitergehende und optimierte Ansätze. Diese hochentwickelten Modelle sind nicht einfach nur „größere“ künstliche neuronale Netze, sondern integrieren innovative Techniken und Architekturen, die es ihnen ermöglichen, größere Leistungen in der Datenverarbeitung und -analyse zu erziehen. Neben innovativen Architekturen hilft auch der Einsatz von spezialisierten Rechenprozessoren wie Grafikkarten und Tensor-Prozessoren, den Rechenaufwand besser zu bewältigen.
Der Sprung von grundlegenden neuronalen Netzen zu den Spitzentechnologien der heutigen KI-Welt ist also nicht nur eine Frage der Skalierung, sondern insbesondere der innovativen Konzeption und Anwendung. Trotz allem basieren die Techniken auf den oben erläuterten Grundlagen der verknüpften Neuronen – nur in optimierter Form.
Grenzen und Herausforderungen
KI-Technologie hat das Potenzial, viele Aspekte unseres Lebens und unserer Wirtschaft zu revolutionieren. Doch wie bei jeder Technologie ist es entscheidend, neben ihrer Funktionsweise und den Möglichkeiten auch ihre Grenzen und Risiken zu verstehen. Drei Punkte möchten wir hierzu erläutern:
- Rechenkapazität und Kosten: Die hohen Anforderungen an die Rechenleistung und die damit verbundenen Kosten sind aktuell noch ein großer Treiber für die Kosten von Training und Implementierung von KI-Modellen, besonders bei tiefen künstlichen neuronalen Netzen. Quantencomputer könnten langfristig eine Lösung bieten, aber wann diese praktisch für diesen Einsatz herangezogen werden können, ist noch unklar.
- Transparenz und Sicherheit: Die „Black-Box“-Natur vieler KI-Systeme stellt in kritischen Anwendungen, in denen Erklärbarkeit und Nachvollziehbarkeit unerlässlich sind, ein erhebliches Problem dar. Auch wenn die Forschung im Bereich erklärbarer KI (Explainable AI) darauf abzielt, transparentere Modelle zu entwickeln, sind noch viele Fragen offen. Zudem müssen auch KI-Modelle ausreichend vor Sicherheitsrisiken und Manipulationen geschützt werden.
- Datenqualität und Ethik: Ein KI-Modell ist nur so gut wie die Daten, mit denen es trainiert wurde. Schlechte oder voreingenommene Daten können zu ungenauen und ethisch problematischen Ergebnissen führen. Fragen der Fairness, des Datenschutzes und der gesellschaftlichen Auswirkungen sind daher ebenfalls wichtig bei der Entwicklung und Anwendung von KI.
Die technischen Details in diesem Artikel geben einen tiefen Einblick in die Funktionsweise und die Herausforderungen der KI. Die verantwortungsbewusste Nutzung dieser fortschrittlichen Werkzeuge liegt letztlich bei den Nutzenden. Im nächsten Artikel dieser Reihe werden wir uns deshalb intensiver mit den ethischen Aspekten auseinandersetzen, die Herausforderungen in diesem Bereich beleuchten und Möglichkeiten aufzeigen, ihnen zu begegnen.
